Machine Learning in Bioinformatics: An Overview
- 28th September 2021
- Posted by: Breige McBride
- Category: Bioinformatics

Curious about machine learning in bioinformatics? Then you are in the right place. This article explains what bioinformatics is, what machine learning is; and how machine learning is used in bioinformatics.
What is Bioinformatics?
Bioinformatics is data analysis for biological data sets. These data sets are often very large so bioinformatics is basically ‘big data analysis’ for biological data. It is an interdisciplinary field where biology, computer science, and statistics meet. Bioinformaticians require knowledge of biology to understand the biological data; and computational and statistical analyses are required to extract meaning from the biological data.
What is Machine Learning?
Machine learning refers to algorithms that have the ability to make predictions or inferences based on previously observed data. We can use it to generate models, which we can then use to predict future events based on existing data.
What is the Difference Between Machine Learning and Artificial Intelligence (AI)?
Machine Learning is a subset of Artificial Intelligence and works as explained above. Meanwhile, an AI has the ability to mimic perceived human intelligence which includes using logic to make decisions and reasoning with humans. An example that demonstrates the difference would be asking your smart speaker for the weather forecast. Machine learning is what is responsible for making a prediction about the weather; however, it is AI that will interpret the command and then issue the response.
Types of Machine Learning Models
As explained above, machine learning involves generating models which predict future events based on existing data. There are many different models to do this but they mainly fall under two categories; regression models and classification models. Some of the most widely used regression models are linear regression, LASSO, and ridge regression. Common classification models include Naive Bayes, Logistic Regression, and Decision Trees. Choosing which specific model to use ultimately depends on the type of data you have and what you want to learn from it. However, classification models are used to assign samples to a fixed number of categories or groups (such as left or right handed) while regression models are used predict the numerical values (such as height or weight).
Machine Learning Model Example: Decision Tree
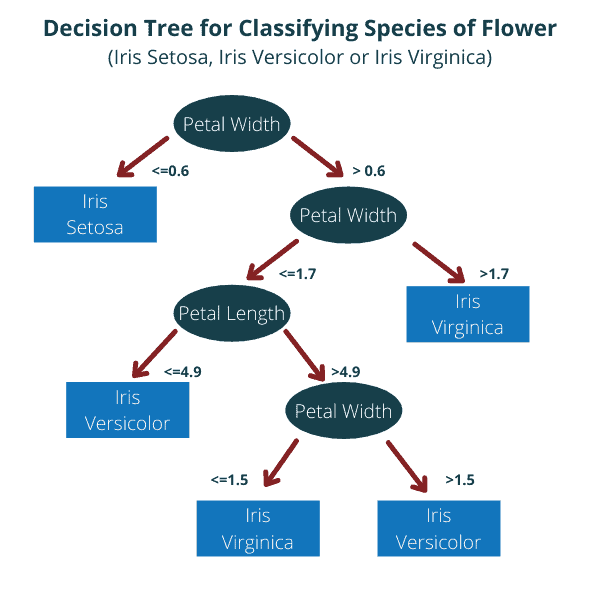
What are Overfitting and Underfitting in Machine Learning?
Machine learning models can range in flexibility. More flexible models can learn complex relationships between predictors and outcomes. For example, predicting career success from personality. However, flexible models can run the risk of ‘overfitting’. Overfitting is when the model matches the training data too closely and therefore becomes worse at predicting new data. The green line in diagram below is an example of overfitting.
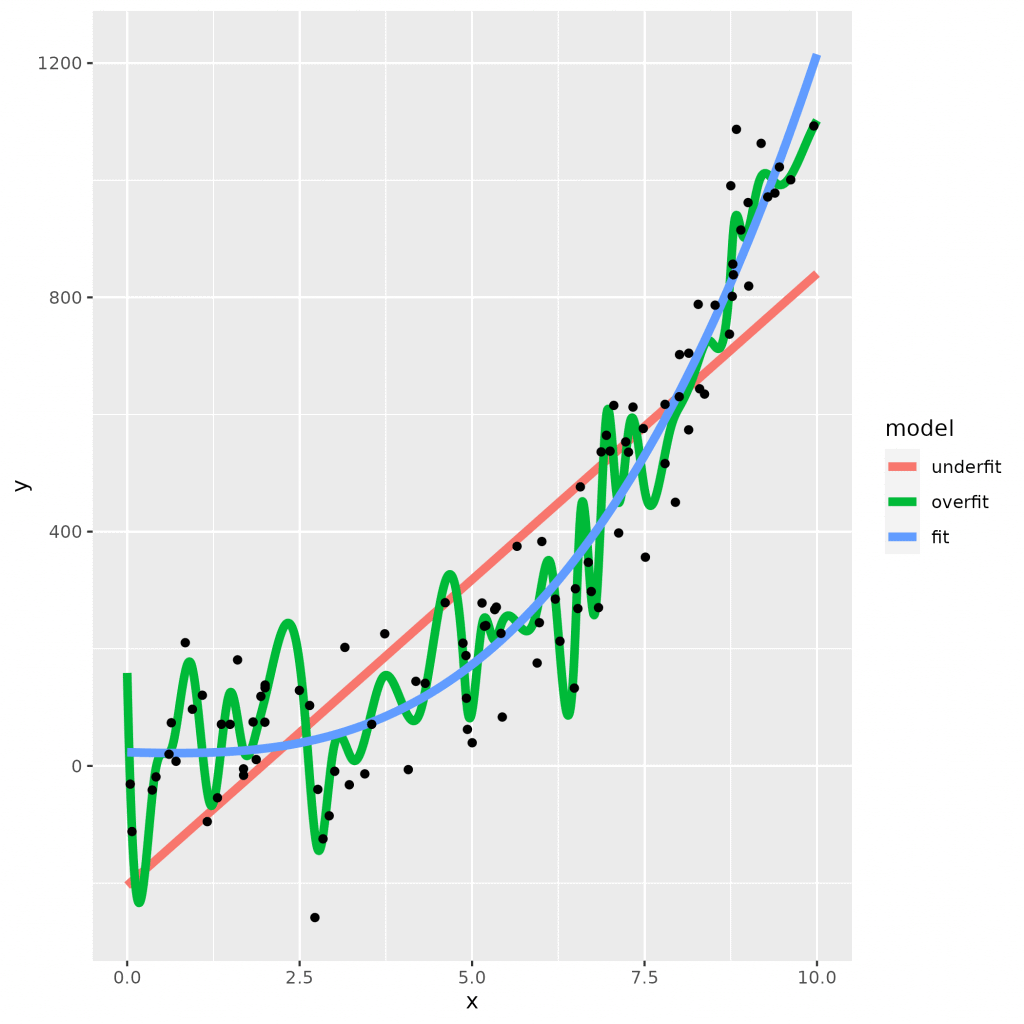
On the other hand, less flexible models can only learn simple relationships between data; e.g. predicting trouser length from height. Even though this means that these models will be less accurate when the relationship between data is more complex, it also means that they will be less likely to overfit when the true relationship between the data is simple.
When a model is unable to accurately capture the relationship between data this can result in ‘underfitting’. These models have high error rates both on new data and on the data that they were trained on. The red line in the diagram above is an example of underfitting.
Machine Learning in Bioinformatics
We can use machine learning in bioinformatics for a variety of applications. These include:
- Gene or clinical signature identification
- Identification of tumour driver mutations
- Classification of patients into groups, e.g. responders and non-responders
- Identification of tumour subtypes
It is important to note that machine learning requires large sample sizes (typically hundreds of samples) so that there is enough data to work with. In drug discovery and development, these sample sizes are usually only available from larger phase 3 clinical trials. However, there are already many large biological datasets available in the public domain which we can apply machine learning to.
Machine Learning as a Service at Fios Genomics
We have a number of cloud-based machine learning tools in our bioinformatics tool kit at Fios. We utilise machine learning on data sets that are large enough to benefit from it and we have a great deal of experience in doing so. Our bioinformaticians have applied machine learning to several confidential projects for clients. However, we are able to demonstrate our experience by sharing this paper which was published in Volume 5, Issue 1 of the BMJ Open Respiratory Research Journal. The paper is entitled Survival prediction in mesothelioma using a scalable Lasso regression model: instructions for use and initial performance using clinical predictors, and Fios bioinformaticians collaborated on it as part of a client project.
If you would like to know whether machine learning would be suitable for an upcoming project which requires bioinformatics support, please contact us. We will be glad to answer any questions you have about machine learning in bioinformatics. Also, We will be happy to learn about your project and advise on the types of bioinformatics analyses that will be best at revealing the insights within your data.
Machine Learning in Bioinformatics Video
This video contains a condensed version of the information available in this blog.
Author: Breige McBride, Content and Social Media Manager, Fios Genomics
Reviewed by Fios Genomics Bioinformatics Experts to ensure accuracy
Similar blogs you may find interesting
What is Bioinformatics – Overview and Examples
Using Biobank Data to Reach Your Research Goals
Cancer Bioinformatics: Data Analysis for Oncology Research
Our Bioinformatics Services
Download RNASeq Data Analysis Report
Fill in the form below to access the data analysis report our team created. Here, bioinformatics analysis of publicly available RNA sequencing (RNASeq) datasets helped to identify genes and pathways associated with psoriasis and the response of psoriatic skin to modulation of the AhR.
Leave a Reply
You must be logged in to post a comment.
