Sequencing vs Analysis: Why the Cost Disparity?
- 4th March 2021
- Posted by: Breige McBride
- Categories: Articles, Sequencing, Single Cell Analysis

The cost of sequencing samples never seems to correlate with the cost of analysis. While with sequencing, costs are relatively straightforward (often including use of lab equipment, reagents etc.), the same is not always said for analysis.
The cost of analysis can be made up of sample number (to an extent), data complexity, type of data, etc., and can be dependent on the specific dataset.
However, even within data sequencing methods and between providers, costs can vary widely. This can be down to where sequencing will be conducted, and how specific and accurate you want your results to be. Additionally, what you are sequencing (for example, RNAseq, single-cell, or whole genome) can also have a huge impact on the cost of data generation.
How has data generation changed?
In computing, Moore’s Law postulates that the cost of computers would halve every two years, while the number of transistors on a microchip (the capability and speed) would double in that same period. For genomic sequencing, the Carlson curve is the equivalent of Moore’s Law. It describes the rate of DNA sequencing or cost per sequenced base as a function of time – and more specifically, Carlson predicted that the doubling time of DNA sequencing technologies, whether using cost or performance as the measurement, would be as fast as Moore’s Law.
Using this law, that cost and time to sequence a genome would halve every two years, it would be expected that from the initial draft of the human genome sequence (at ~$300 million in 2000), that in 2021 it would cost roughly $200,000 per genome. However, this is nowhere near the case.
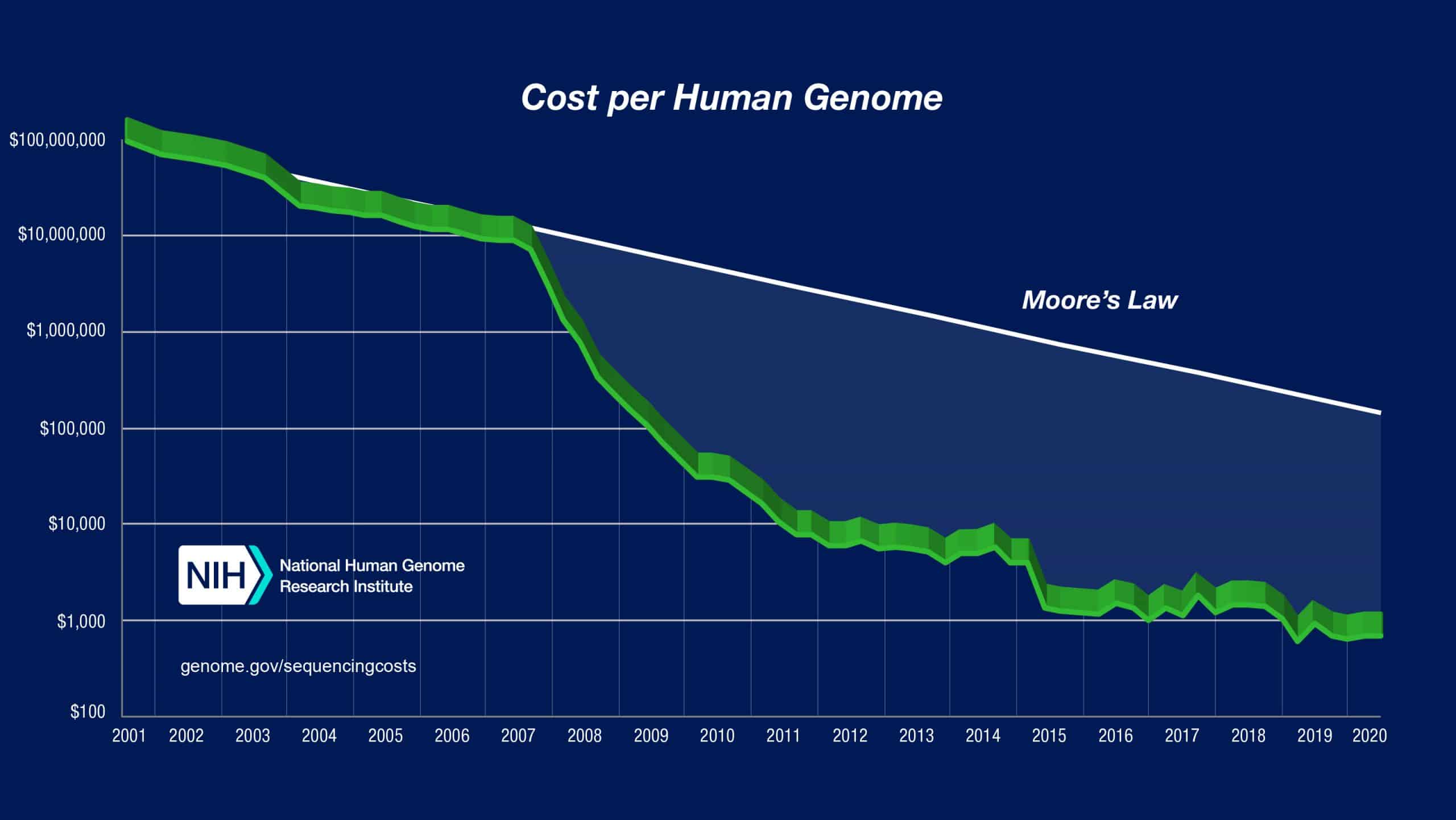
Image from NHGRI (2020).
In 2008, the reduction in cost of genomic sequencing started to outpace Moore’s Law and the Carlson curve to an impressive degree. New high-throughput sequencing machines became the norm, taking over from the Sanger sequencing machines. This both reduced time and cost. Now, a full human genome can be sequenced in a day for roughly $1,000.
But this reduction in cost and time has just been for data generation. While the cost of analysis has not followed a similar line, every penny spent on data generation is wasted if the data is not analysed.
Why is analysis so expensive compared to sequencing?
It’s all relative. Unlike sequencing, where as you scale up number of samples in a study, the cost per sample goes down, the analysis does not always follow the same trend. With the ability to generate more data comes the challenges of analysing it all. While specific types of sequencing have been able to reduce cost thanks to high-throughput techniques, the complexity of analysis has grown which is often where the analysis cost is focused on.
Additionally, with greater dataset sizes and complexity comes inherent challenges in storing and transferring data. Storage of all sequenced data for a single human genome is roughly 1.5GB. If you start analysing multiple genomes, or integrating other ‘omics datasets into your research, this starts to grow quickly. This all has associated costs, which are not insignificant.
Biological studies are now generating datasets of similar size and computational demands as other, more traditionally data-heavy disciplines. In some cases, the sheer amount of data generated during trials can outpace the ability to analyse it.
Quality analysis will cost money. But it will also ensure you make the most out of your generated data and therefore your research.
Read more
The real cost of sequencing: scaling computation to keep pace with data generation
Leave a Reply
You must be logged in to post a comment.
